There's been some great progress with Fovea, a platform using remote, webcam-based eye tracking for verification and interaction.
overview
Fovea is a web platform that enables interactive content delivery through analyzing viewing patterns. It's an initiative Patrick Adelman and I started earlier this year, and we recently published a series of blog posts with some major updates:
- Overview of the platform
- Fovea's first application in improving the way employees are trained remotely
- The future of Fovea, our upcoming partnership with AP and in market research
The following is a condensed version of our progress and application in the field of employee training.
the challenge
In the first stage, we're making learning more interactive. We're doing this through combining object-level data with real-time eye tracking.
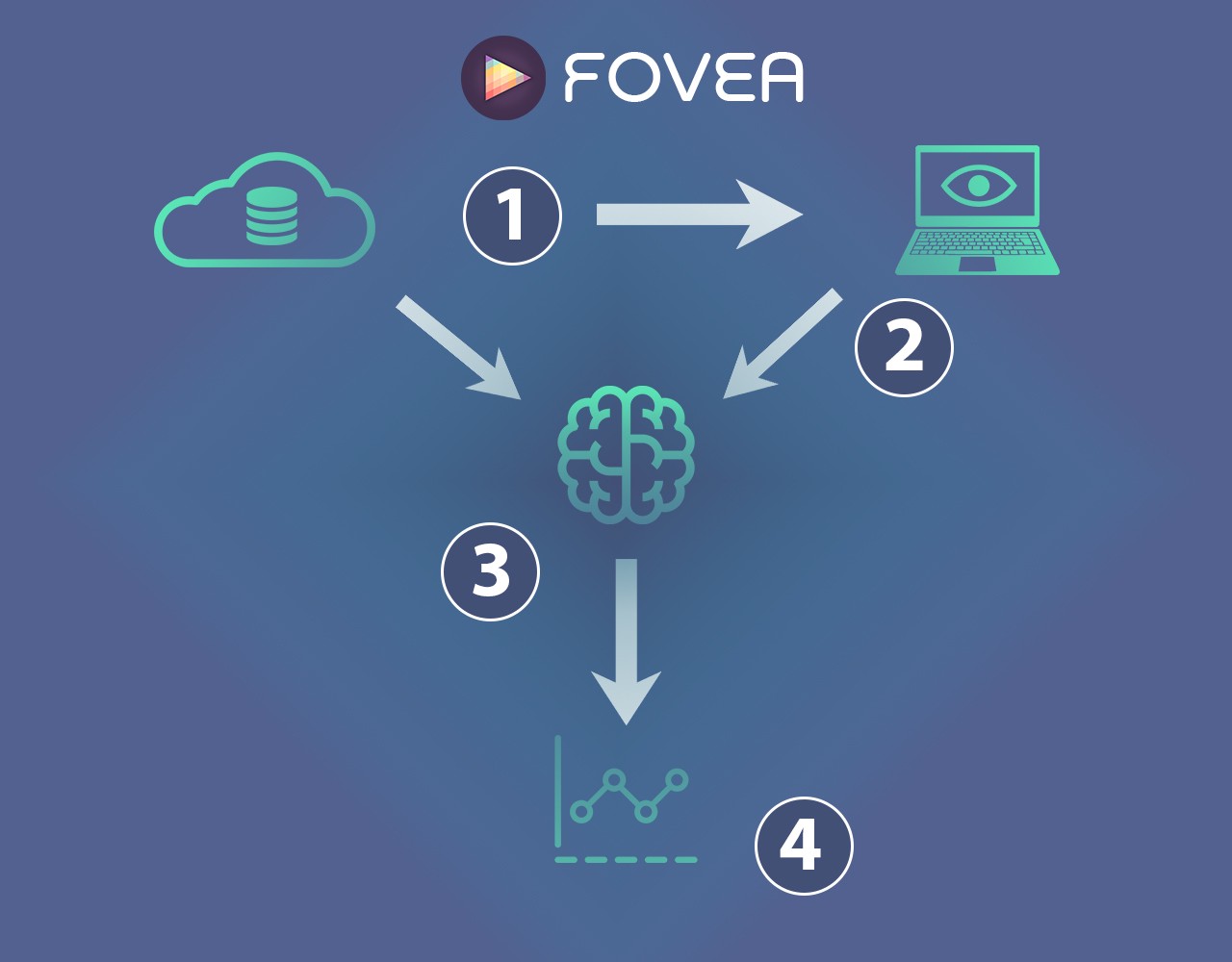
- Content is uploaded to the cloud by the user. This could be video, training documents, graphics, photos, or any other form of media. State-of-the-art processing algorithms are used to analyze the content and prepare it for viewing.
- Viewers enable the standard webcam on their laptop or stand in front of a display with a simple camera. No special software is needed, Fovea can run entirely through a web browser. If desired, Fovea can verify which user is currently watching — for cases of remote training or online education, this will be useful.
- While the viewer is viewing the content, Fovea tracks and processes their eye movements in real time, in connection with the analysis from step 1. This allows Fovea to understand exactly what is drawing a viewer’s attention and serve content based on that.
- Analytics are generated for the user to determine which content was effective and how to better design viewer experiences going forward.
training pilot study
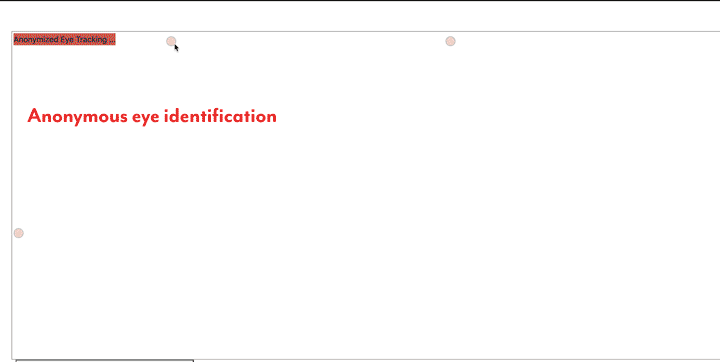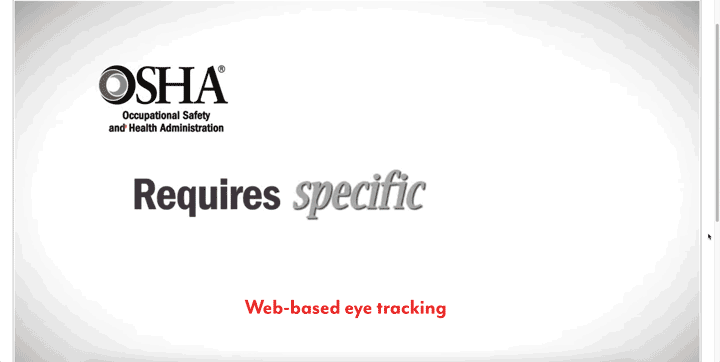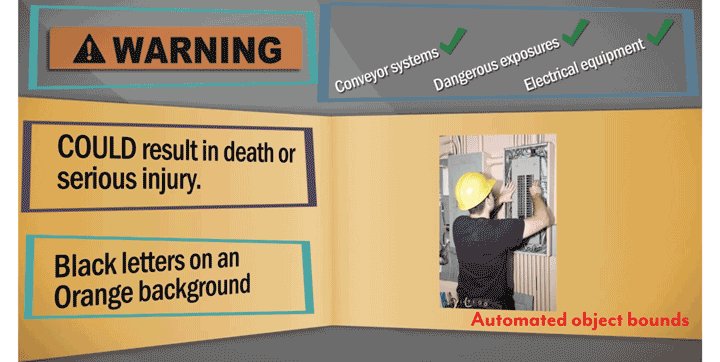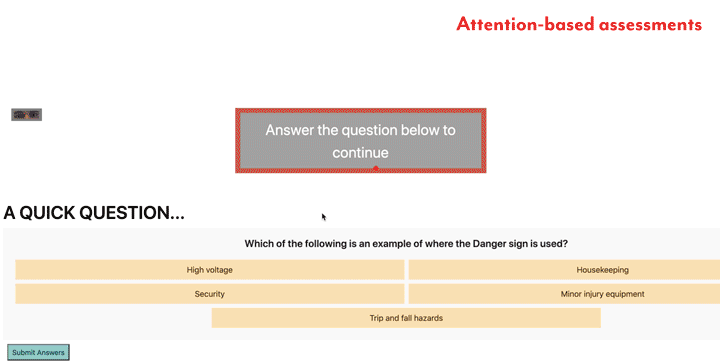
We selected a video on OSHA safety signs that are commonly encountered in manufacturing facilities, and specified areas of interest (AOIs) that a training manager may label as important.
Next, we recruited a small number of participants online through MTurk, who viewed the training video and answered quizzes, triggered at various times. Each personalized quiz question was based on the AOI they viewed least. In other words, if important regions in the video weren’t attended to as much as they should have, participants were presented with a multiple-choice quiz that drew their attention to areas that were labeled as important.
Eye tracking was done through the participants’ web camera, after detection of the eye region, shown at all times to the participants so they were aware of what data was being analyzed. We did not need to store any image data, and only used the frame-by-frame footage to extrapolate eye tracking coordinates client-side.
results
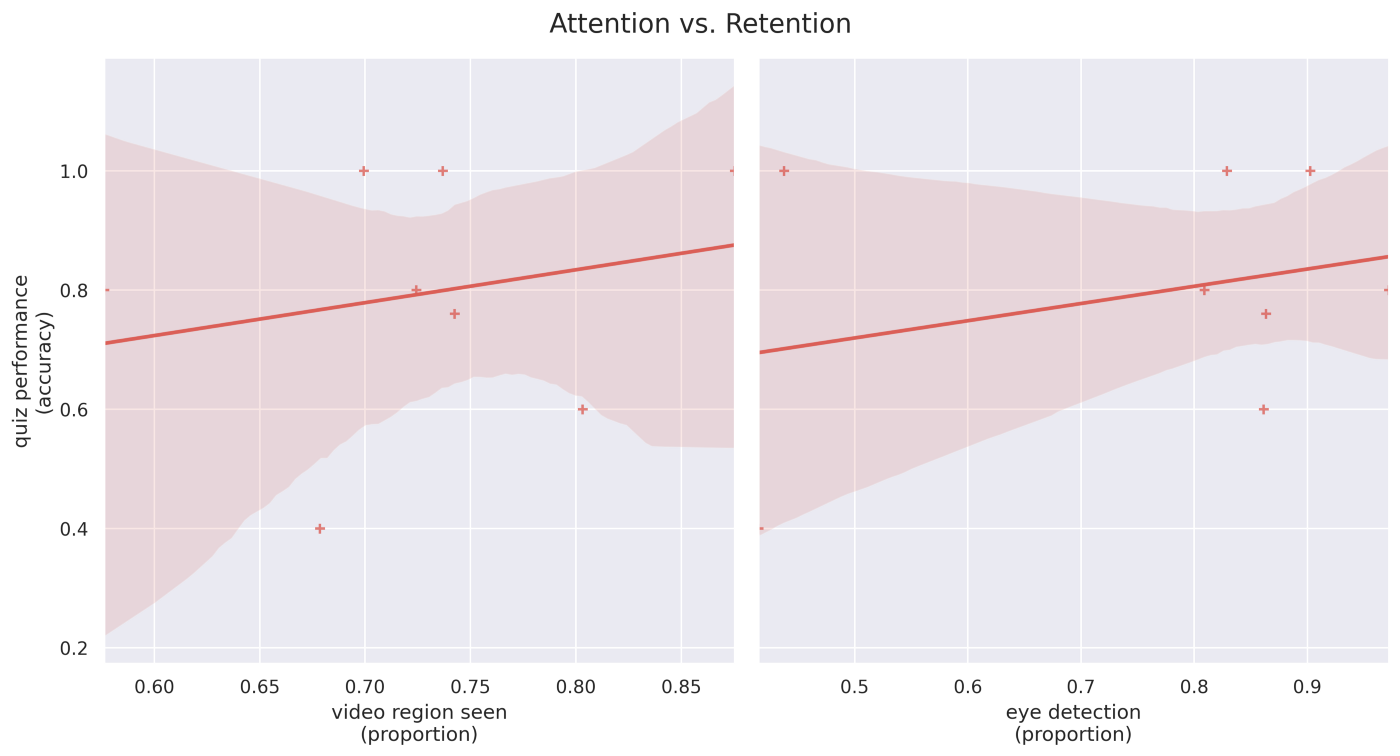
We were initially worried about the problems posed by the variety of environmental effectors on the quality of eye tracking data, e.g. poor lighting, laptop setup. However, we found that our eye detector was able to detect the eye region with high confidence (> 85% of the time), and the majority of samples (>74%) detected that viewers were looking at the video region.
Next, I was very curious about how well our dynamic quiz performance corresponded with looking time. We're not publishing these results anytime soon since it's just a feasibility study, but we were encouraged to see that we not only were able to present quiz questions based on viewed regions, in real time, but this actually related to how well participants performed on the assessments.
interactive viewing
The novelty of Fovea relies on using eye tracking in real time to effect content delivery. In this application, the quiz questions were personalized to each viewer, and the question related to an AOI that they viewed least in the preceding section of the video. In the image below, sections are labeled Danger, Warning, Caution, Notice and General Safety, and the selected sequence of quiz questions depended on AOIs that were viewed least (red border).
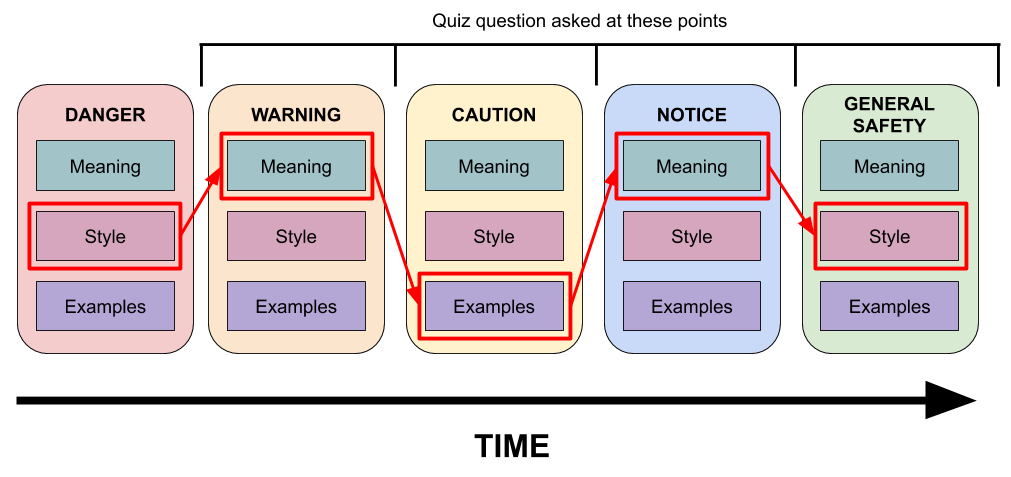
Through presenting assessments dynamically, we guided viewers to paying attention to those AOIs that were quizzed on ~ 7% more of the time in the subsequent region. This type of interactivity is valuable in learning. You can read more on our full post.
what's next?
Next, we're partnering with the Associated Press to present news content interactively. This is something I'm very passionate about, every time I have to immediately close or mute a video on a news website since it never presents what I want to see. Inconvenience aside, interactive news content delivery can makes facts more engaging and personalized. Below is a preview of what you can expect: object-specific data is paired with real-time eye tracking to automate editing.

Read more about our future goals here.